Appex 11 – Penalized Regression in R
STA 363 - Spring 2023
Set up
Login to RStudio Pro
- Note: if you are off campus, you will need to use a VPN to connect
- Go to rstudio.deac.wfu.edu

Step 1: Create a New Project
Click File > New Project
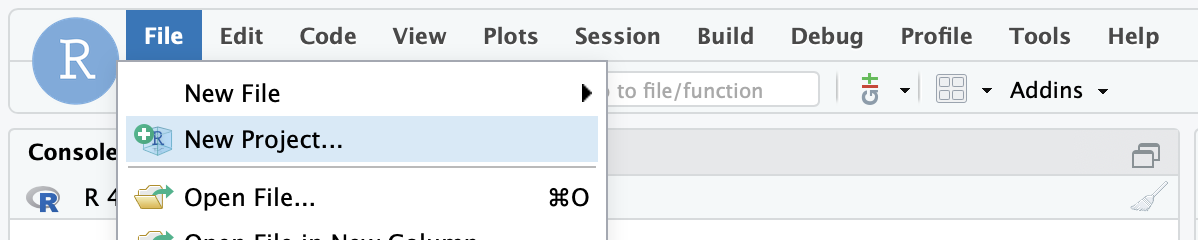
Step 2: Click “Version Control”
Click the third option.
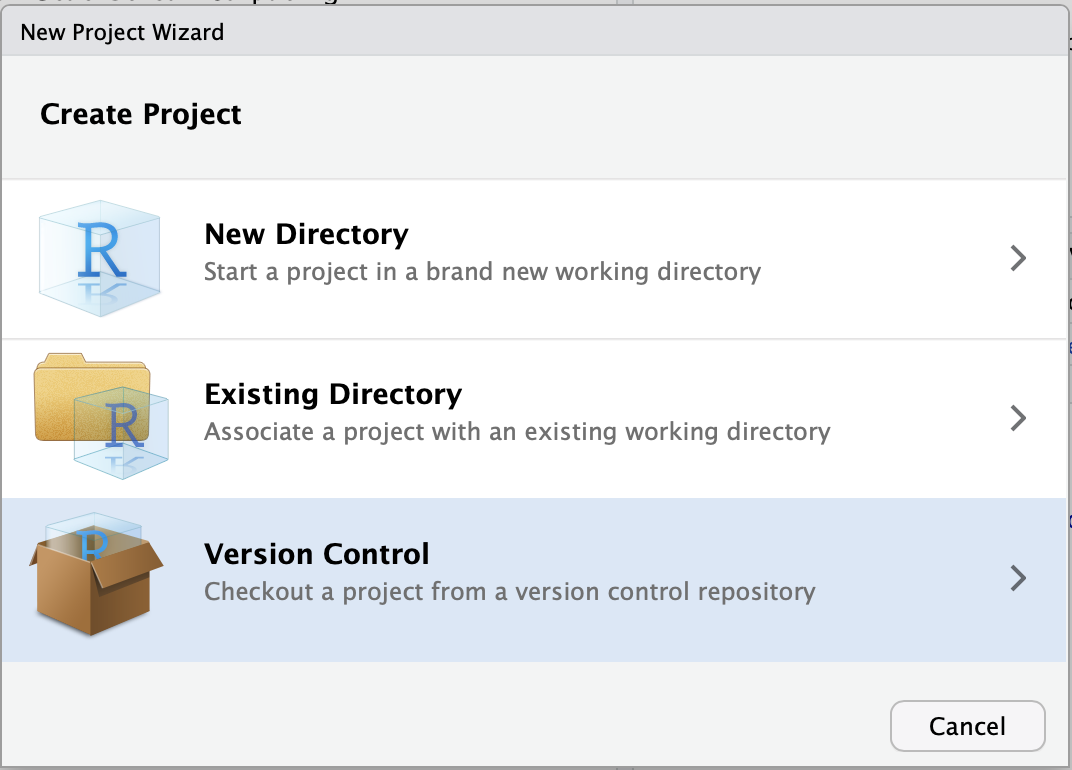
Step 3: Click Git
Click the first option
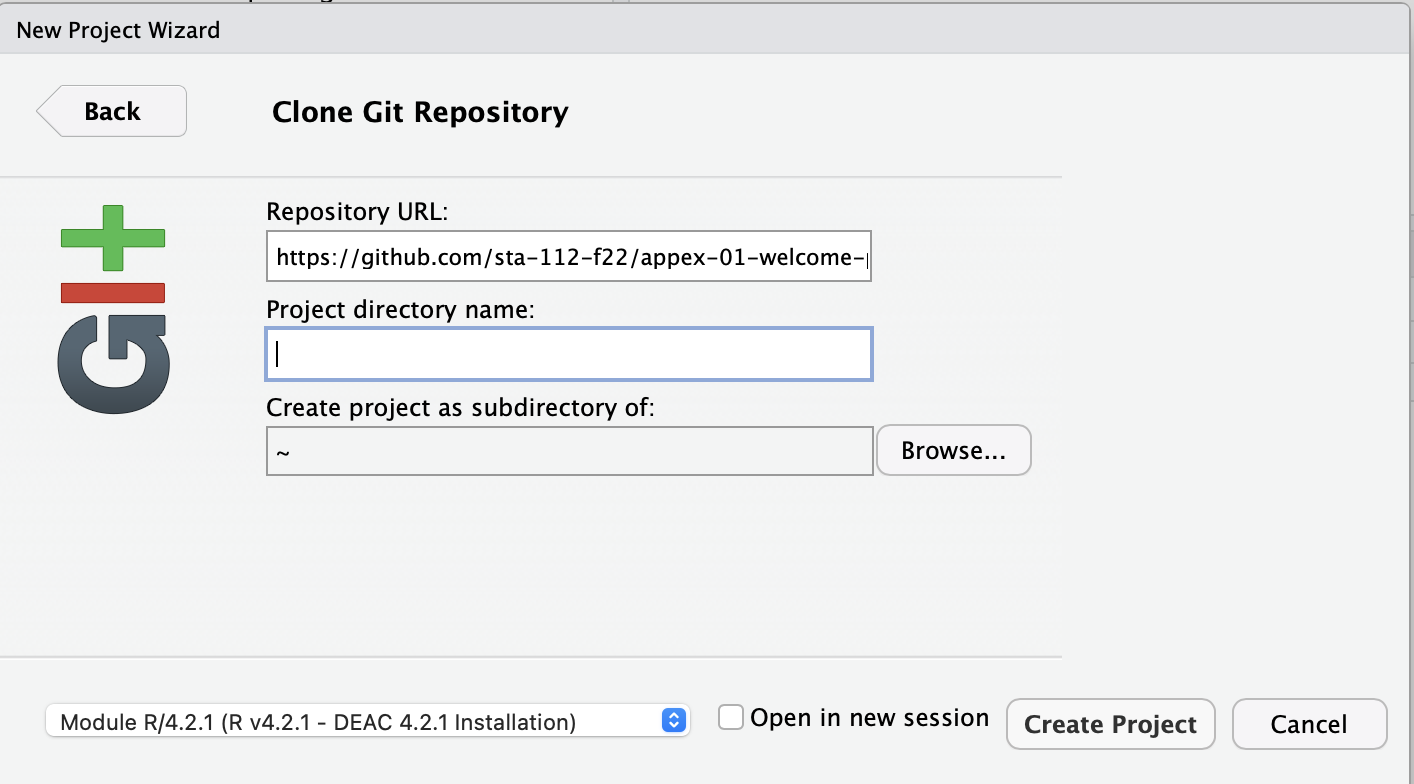
Step 4: Copy my starter files
Paste this link in the top box (Repository url):
https://github.com/sta-363-s23/11-appex.git
Part 1
- Examine the
Hittersdataset by running?Hittersin the Console - We want to predict a major league player’s
Salaryfrom all of the other 19 variables in this dataset. Create a visualization ofSalary. - Create a recipe to estimate this model.
- Add a preprocessing step to your recipe, scaling each of the predictors
Part 2
- Add a preprocessing step to your recipe to convert nominal variables into indicators
- Add a step to your recipe to remove missing values for the outcome
- Add a step to your recipe to impute missing values for the predictors using the average for the remaining values NOTE THIS IS NOT THE BEST WAY TO DO THIS WE WILL LEARN BETTER TECHNIQUES!
Part 3
- Set a seed
set.seed(1) - Create a cross validation object for the
Hittersdataset - Using the recipe from the previous exercise, fit the model using Ridge regression with a penalty \(\lambda\) = 300
- What is the estimate of the test RMSE for this model?
Part 4
- Using the
Hitterscross validation object and recipe created in the previous exercise, usetune_gridto pick the optimal penalty and mixture values. - Update the code below to create a grid that includes penalties from 0 to 50 by 1 and mixtures from 0 to 1 by 0.5.
- Use this grid in the
tune_gridfunction. Then usecollect_metricsand filter to only include the RSME estimates. - Create a figure to examine the estimated test RMSE for the grid of penalty and mixture values – which should you choose?
Part 5
- Using the final model specification, extract the coefficients from the model by creating a
workflow - Filter out any coefficients exactly equal to 0
